“为什么我的RVC训练总卡在99%?报错提示‘中文路径不兼容’!”
这是RVC变声器用户群里最高频的抱怨——明明按教程操作,却因路径含中文或空格导致训练崩溃。本文将用3步排查法+5个内行技巧,彻底解决这一顽疾。
准备/底层逻辑:中文路径为何会成为RVC的“隐形杀手”?
RVC基于PyTorch框架开发,其底层依赖的CUDA加速库对非ASCII字符路径(如中文、日文、空格)存在天然兼容性问题。当训练脚本尝试读取中文路径下的音频文件时,会触发以下连锁反应:
- 文件系统解析失败:CUDA内核无法正确映射中文路径到内存地址。
- 数据加载中断:PyTorch的
DataLoader直接抛出UnicodeDecodeError。 - 模型训练崩溃:梯度计算因数据流断裂而终止。
内行提醒:即使将音频文件拖入项目文件夹,若文件夹名含中文(如“我的RVC训练集”),仍会触发报错——路径污染比文件内容污染更致命。
核心执行步骤:3招彻底根治中文路径问题
Step 1:全盘路径“英文化”改造
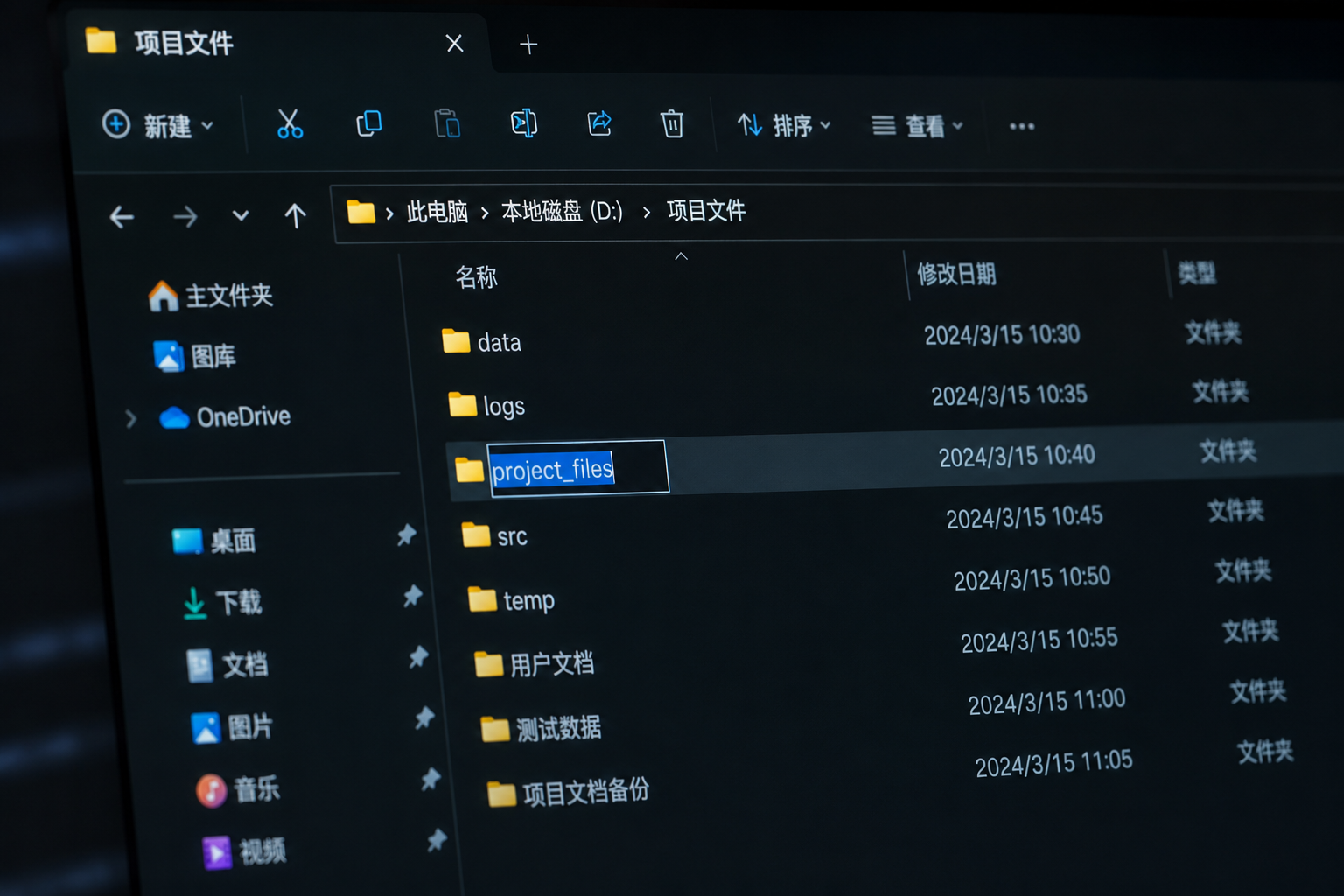
- 操作:将RVC项目目录、音频文件夹、模型输出路径全部改为纯英文(如
D:\RVC_Train\)。 - 避坑:避免使用
!@#$%^&*等特殊符号,部分旧版PyTorch对符号路径支持不稳定。 - 内行技巧:在命令行中用
dir /x命令查看文件夹的8.3短名称(如MYRVC~1),可直接用短名称替代中文路径。
Step 2:强制指定数据加载路径
在RVC的train.py脚本中,找到数据加载部分(通常包含Dataset类),手动指定英文路径:
# 错误示例(含中文路径)
dataset = AudioDataset(root_path="D:/我的训练集/")
# 正确示例(纯英文路径)
dataset = AudioDataset(root_path="D:/RVC_Train/") 内行提醒:若使用
--data_dir参数启动训练,需在命令行中用双引号包裹路径(如python train.py --data_dir "D:/RVC_Train/"),避免空格被解析为参数分隔符。
Step 3:CUDA环境“纯净化”重置
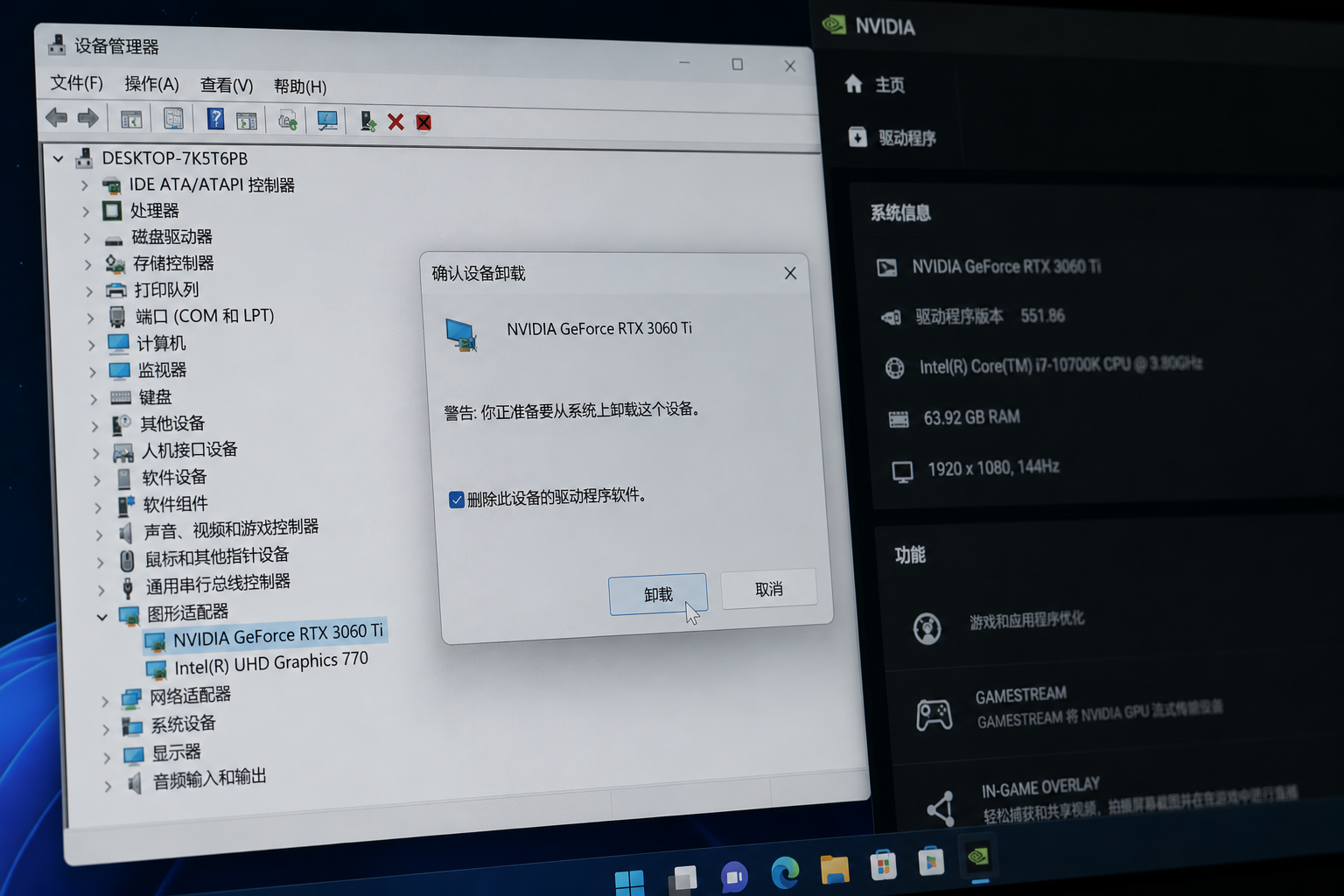
- 卸载旧版CUDA:通过NVIDIA控制面板彻底删除现有驱动(版本需与PyTorch匹配,如RVC 2.0推荐CUDA 11.8)。
- 关闭中文输入法:训练时强制切换为英文输入法(部分输入法会注入系统钩子导致CUDA冲突)。
- 重启内核:在Jupyter Notebook或PyCharm中,执行
Kernel → Restart清除残留路径缓存。
⚠️ 避坑与防御:这些“潜规则”90%用户不知道
- 虚拟环境隔离:用
conda create -n rvc_env python=3.10创建独立环境,避免主环境中的中文路径污染。 - 日志文件分析:若报错仍存在,检查
logs/train.log中的完整错误堆栈(重点搜索UnicodeError或FileNotFoundError)。 - 竞品对比:相比So-VITS-SVC,RVC对路径的敏感度更高——后者可通过
--ignore_path_error参数强制跳过路径检查(但可能引发其他问题)。
🚀 终极解决方案:RVC中文路径修复工具包
包含以下工具:
- 路径批量重命名脚本:一键将中文路径转换为英文+数字组合。
- CUDA环境检测工具:自动匹配PyTorch与CUDA版本。
- 训练日志解析器:快速定位报错根源。