为什么你的RVC推理比别人慢10倍?
同样的模型,别人的RVC推理秒出结果,你的却要等半天甚至直接卡死?
问题不在模型,不在电脑配置,而在GPU设置。
90%的RVC用户,装完环境就直接开跑,完全没有碰过推理参数。默认配置是为”能跑”设计的,不是为”跑得快”设计的。本文手把手教你把推理速度拉满。
一、先搞清楚:RVC推理慢的根本原因
RVC(Retrieval-based Voice Conversion)的推理过程,本质是把一段音频通过模型进行特征转换再输出。这个过程中,GPU的利用率直接决定速度。
默认配置的三个致命问题:
- 只用CPU推理:没有正确配置CUDA,PyTorch自动回退到CPU,速度差10倍以上
- 批处理大小(batch size)过小:GPU算力没有被充分利用,大量时间浪费在等待上
- 精度冗余:用FP32跑推理,实际上FP16甚至INT8对音质影响极小,但速度快一倍
先确认你的环境到底有没有在用GPU。
打开命令行,进入RVC所在目录,执行:
import torch
print(torch.cuda.is_available()) # 返回True才算GPU可用
print(torch.cuda.get_device_name(0)) # 显示你的显卡型号如果第一步返回False,先别往下看,去装CUDA和对应版本的PyTorch,这是前提。
二、核心提速设置:3个参数改完立竿见影
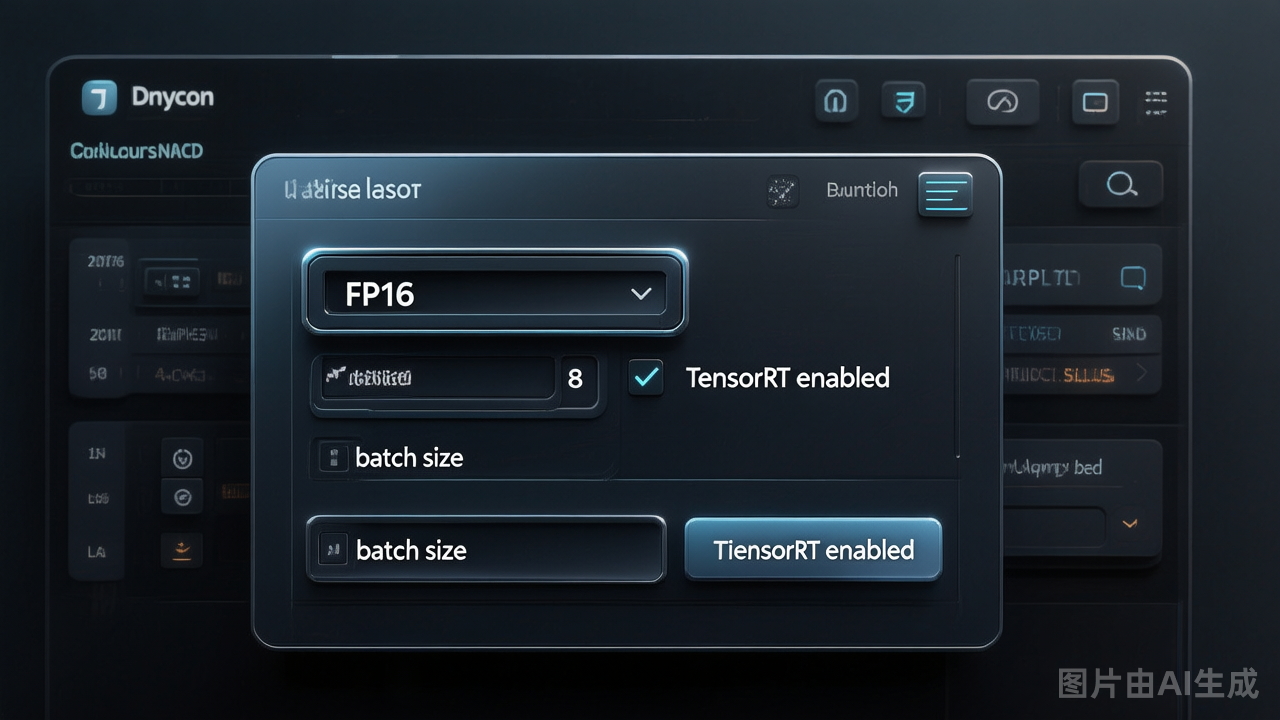
参数一:开启FP16半精度推理
这是性价比最高的优化,几乎没有音质损失。
在infer.py或服务启动参数中找到推理精度设置,将:
precision = "float32" # 默认改为:
precision = "float16" # 半精度内行提醒: 某些老显卡(GTX 10系列及更早)对FP16支持不佳,强行开启可能报错,此时保持FP32即可,不要用INT8替代,INT8在音频模型上容易出现爆音。
参数二:调大批处理大小(Batch Size)
RVC的实时变声和离线推理都支持批处理。默认batch_size=1,GPU利用率往往不到20%。
建议按显存大小设置:
| 显存大小 | 推荐 batch_size | 预估提速倍数 |
|---|---|---|
| 4GB | 2~4 | 2~3x |
| 6~8GB | 4~8 | 3~5x |
| 8GB+ | 8~16 | 5~10x |
修改位置:在推理脚本中找到batch_size参数,或直接启动时加参:
python infer.py --batch_size 8内行提醒: 调大batch_size的同时,把输入音频先切成小段(5~10秒一段),再批量喂给模型,比直接扔一整首歌进去效率高得多。
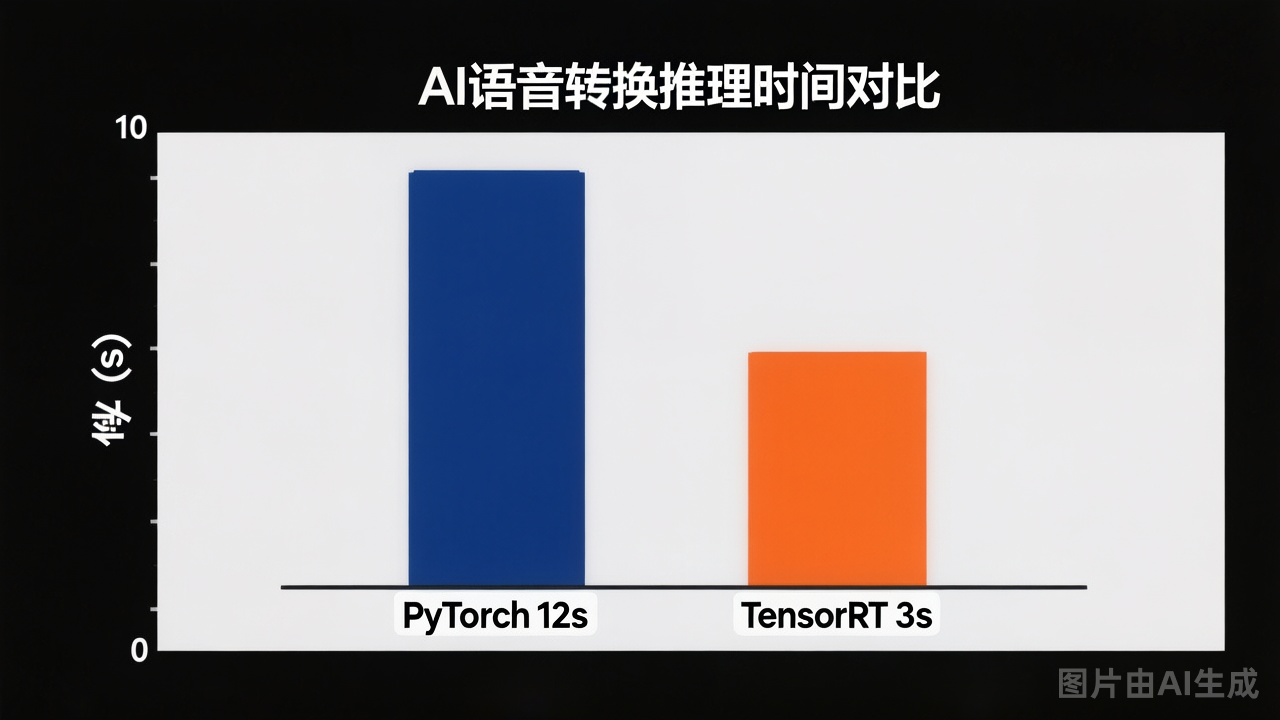
参数三:开启TensorRT加速(高端显卡专属)
如果你用的是RTX 30系列及以上的N卡,TensorRT是终极武器。
TensorRT会把模型权重做针对性优化,推理速度比普通PyTorch快2~3倍。步骤:
- 安装TensorRT(需与CUDA版本严格对应,这是最容易踩的坑)
- 将RVC模型转换为TensorRT格式(
.engine文件) - 推理时加载
.engine模型而非原始的.pth
三、实时变声场景的额外优化
如果你用RVC做实时变声(直播、语音聊天),上述设置还不够,需要额外处理延迟问题。
降低采样缓冲区间
实时变声的核心指标是延迟,不是纯推理速度。RVC默认的输入缓冲是4096采样点,高延迟的罪魁祸首。
在实时推理脚本中找到block_size或buffer_size,将其减半:
buffer_size = 2048 # 原为4096,减半降低延迟固定采样率,避免动态重采样
很多人的RVC实时推理慢,是因为每次都在动态重采样。在启动前固定输入输出采样率:
TARGET_SR = 40000 # 固定为模型训练时的采样率
# 不要使用librosa.load的默认行为,它每次都会检测四、这些”提速秘籍”其实是坑
踩坑的人太多了,专门列出来:
❌ 用多线程强行并发推理
RVC推理是显存密集型操作,多线程并发只会让显存溢出(OOM),速度反而更慢。GPU推理用批处理,不要用多线程。
❌ 盲目升级到最新PyTorch
新版本PyTorch不一定更快,有时反而引入regression。RVC社区验证过的稳定组合是:PyTorch 1.13 + CUDA 11.7,不要盲目追新。
❌ 关掉特征检索(Index)来提速
有人建议删除.index文件来加速,确实快,但音质会明显下降,尤其对训练数据量少的模型。正确的做法是将index放在高速SSD上,而不是删除它。
五、一键检测:你的设置到底对不对
把下面这段代码保存为check_gpu.py,运行它,30秒告诉你当前配置有没有问题:
import torch
import time
def benchmark_rvc():
if not torch.cuda.is_available():
print("❌ 未检测到GPU,正在使用CPU推理,速度极慢!")
return
device = torch.device("cuda")
# 模拟RVC推理的矩阵运算
dummy_input = torch.randn(1, 1024, 256).to(device)
model_dummy = torch.nn.Sequential(
torch.nn.Linear(256, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 256)
).to(device).half() # FP16
# 预热
for _ in range(10):
model_dummy(dummy_input.half())
# 计时
start = time.time()
for _ in range(100):
model_dummy(dummy_input.half())
elapsed = time.time() - start
print(f"✅ GPU: {torch.cuda.get_device_name(0)}")
print(f"✅ FP16推理100次耗时: {elapsed:.3f}s")
print(f"✅ 预计RVC推理速度: {100/elapsed:.1f}x 相对CPU")
benchmark_rvc()跑完之后,如果FP16推理100次耗时超过2秒,说明你的GPU设置还有优化空间。
总结
RVC推理速度慢,99%的情况不需要换模型、不需要换显卡,只要改对这三个地方:
- 开启FP16半精度 — 无音质损失,提速约1.5~2倍
- 调大Batch Size — 充分利用GPU,提速3~10倍
- 高端卡开TensorRT — 额外再提速2~3倍
三管齐下,提速10倍是完全可以达到的。